
- 3.87 mm overall test MAE across fat, loin, and total tissue depth
- 2.43 mm backfat MAE — approaching the ultrasound operator standard
- ≈ 7 ms end-to-end inference / frame on a single A100 with the UNet front-end
- 319 sow & gilt instances (6,705 frames) from two independent facilities
Abstract
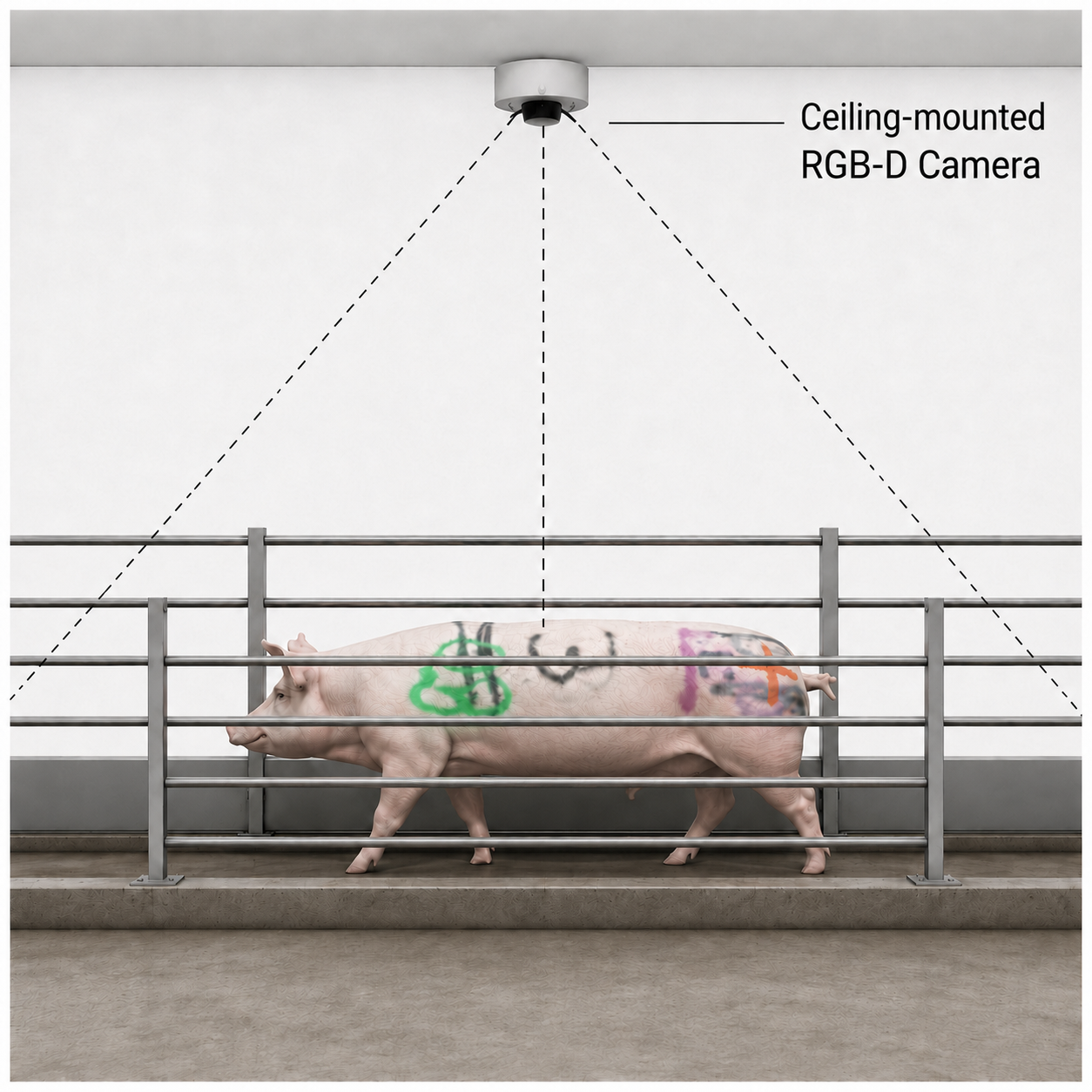
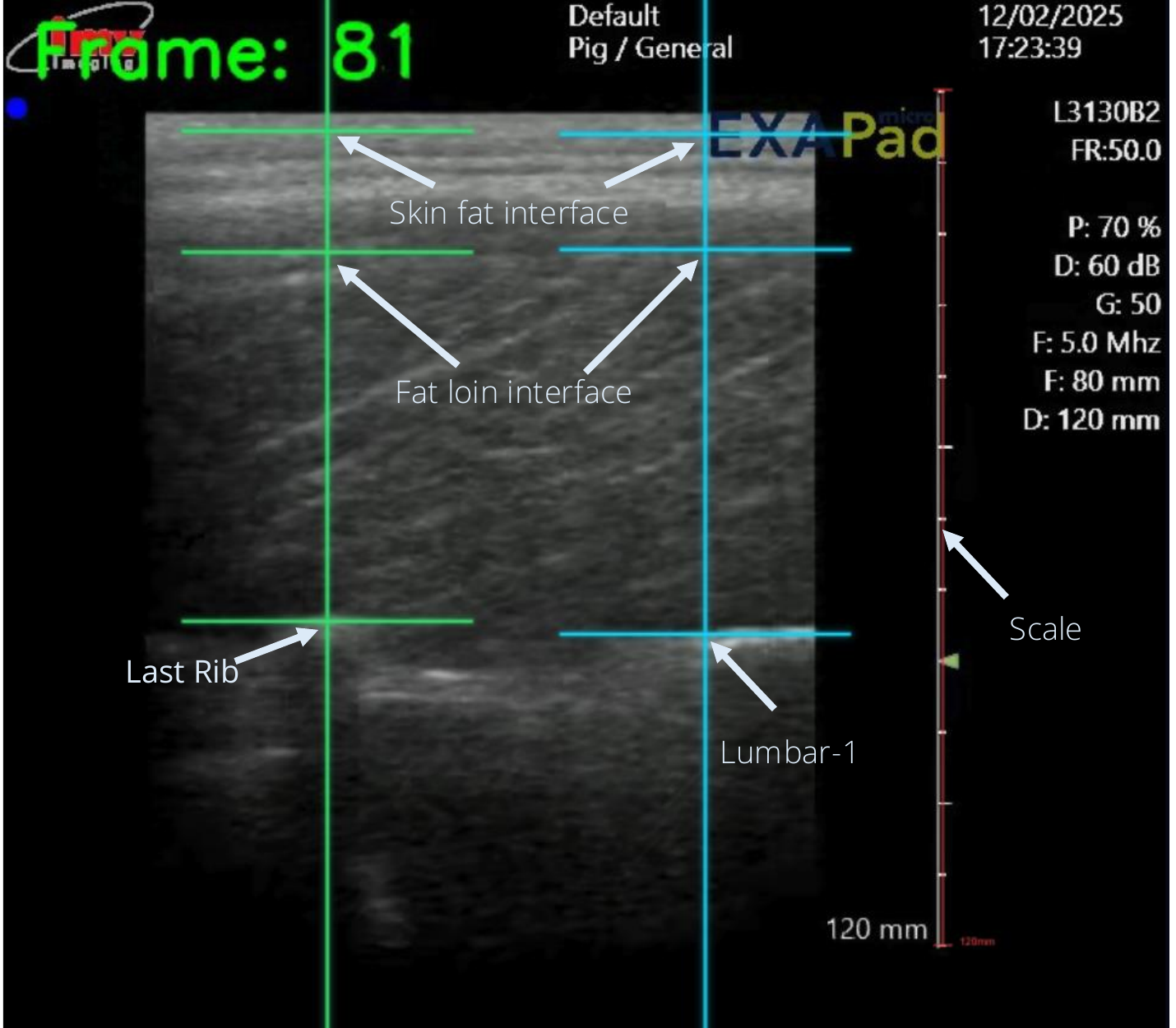
Sow body condition is an important indicator for growers as it has a large impact on lactation performance and piglet survival. However, body condition measures used during production, such as visual scoring and calipers, correlate poorly with underlying tissue composition. Ultrasound scans can provide direct measurements of subcutaneous backfat thickness and loin muscle depth, but their operation is labor intensive and not scalable for production. We present PigFormer, an end-to-end two-stage system that takes raw depth frames from a ceiling-mounted RGB-D camera and predicts subcutaneous backfat thickness, loin muscle depth, and total tissue thickness at the last rib. Stage 1 is a geometric front-end that converts raw depth into a standardized height map via SAM3-to-MaskDINO segmentation distillation, ground-plane removal, and orientation normalization. Stage 2 is a Slice Attention Encoder that treats each height map as a sequence of cross-sectional slices and captures spatial relationships along the full dorsal surface. On a multi-site dataset of 319 sow and gilt instances (6,705 frames) from two facilities, PigFormer achieves 2.43 mm backfat MAE and 3.87 mm overall MAE. It outperforms strong single-stage ResNet-18 and ViT-small baselines that feed raw depth directly to a pretrained backbone, isolating the contribution of Stage 1.
Method
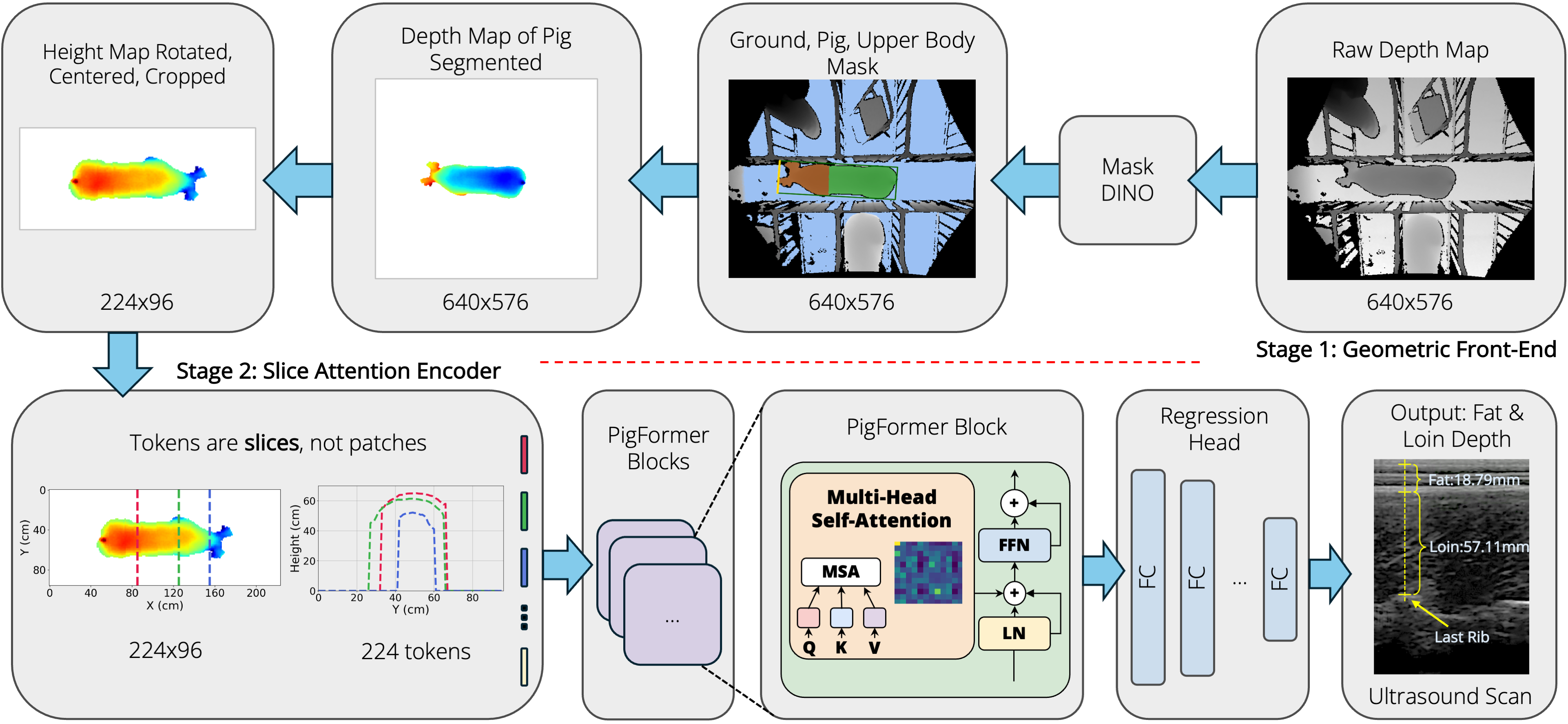
Geometric front-end
Raw depth frames are turned into a canonical 96 × 224 height map. A depth-only MaskDINO segmenter — distilled from SAM3-on-RGB pseudo-labels so it needs no color or text prompt at deployment — isolates the pig. RANSAC removes the ground plane, and a minimum-area-rectangle long axis rotates every animal to face right. The result is a metric, top-down height image that is invariant to where the pig stood under the camera.
Slice Attention Encoder
The height map is read as a sequence of 224 cross-sectional slices along the spine, each a 96-d token. A single RoPE transformer encoder layer (8 heads) relates slices along the full dorsal surface; a concatenated mean + max pool feeds a small MLP head that regresses backfat, loin, and total tissue depth at the last rib. One layer is optimal at this data scale — deeper encoders overfit.
Dataset
PigFormer is trained and evaluated on a multi-site collection of 319 sow and gilt instances (6,705 depth frames) recorded with ceiling-mounted Azure Kinect / Orbbec cameras at two independent facilities — Michigan State University (116 instances) and the University of Nebraska–Lincoln (203 instances). Ground-truth backfat and loin depths come from slaughter-lab ultrasound at the 12th rib. Splits are made at the animal level: roughly 20% of unique IDs are held out as a fixed test set and the remainder is divided into four cross-validation folds, so no animal ever appears in more than one split.
Results
Held-out test results on 79 sow / gilt instances. MAE in mm. Per-frame inference measured on A100 with batch = 1 (MaskDINO Stage 1 in fp16; UNet Stage 1, single-stage backbones, and PigFormer Stage 2 in fp32). Single-stage baselines feed raw depth directly to an ImageNet-pretrained backbone and predict fat and loin only (total is ŷf + ŷl at evaluation). PigFormer numbers are 4-fold cross-validation ensembles with output aggregation. Best MAE in bold.
| Method | Backbone | Inference (ms / frame) | MAE (mm) ↓ | ||||
|---|---|---|---|---|---|---|---|
| Stage 1 | Stage 2 | Fat | Loin | Total | Overall | ||
| ViT-small (single-stage) | ViT-S/16 | — | 4.98 | 3.57 | 7.29 | 8.16 | 6.34 |
| ResNet-18 (single-stage) | ResNet-18 | — | 2.88 | 2.88 | 6.10 | 5.81 | 4.93 |
| PigFormer | MaskDINO (R50-300q-9L) | 106.92 | 0.50 | 2.43 | 5.01 | 4.19 | 3.87 |
| PigFormer | Pruned MaskDINO (R18-50q-5L) | 52.73 | 0.50 | 2.34 | 5.27 | 4.20 | 3.94 |
| PigFormer | UNet (MobileNetV3-Small) | 6.58 | 0.50 | 2.40 | 5.20 | 4.26 | 3.95 |
| Human Ultrasound Std | — | — | — | 1.30 | 2.02 | 2.29 | 1.87 |
End-to-end PigFormer with the UNet Stage 1 runs in ≈ 7 ms / frame on a single A100, fast enough for real-time monitoring on an installed-camera stream. The pruned MaskDINO retains the detection-style inductive bias for out-of-distribution content (handlers, empty pens) at half the latency of the original.
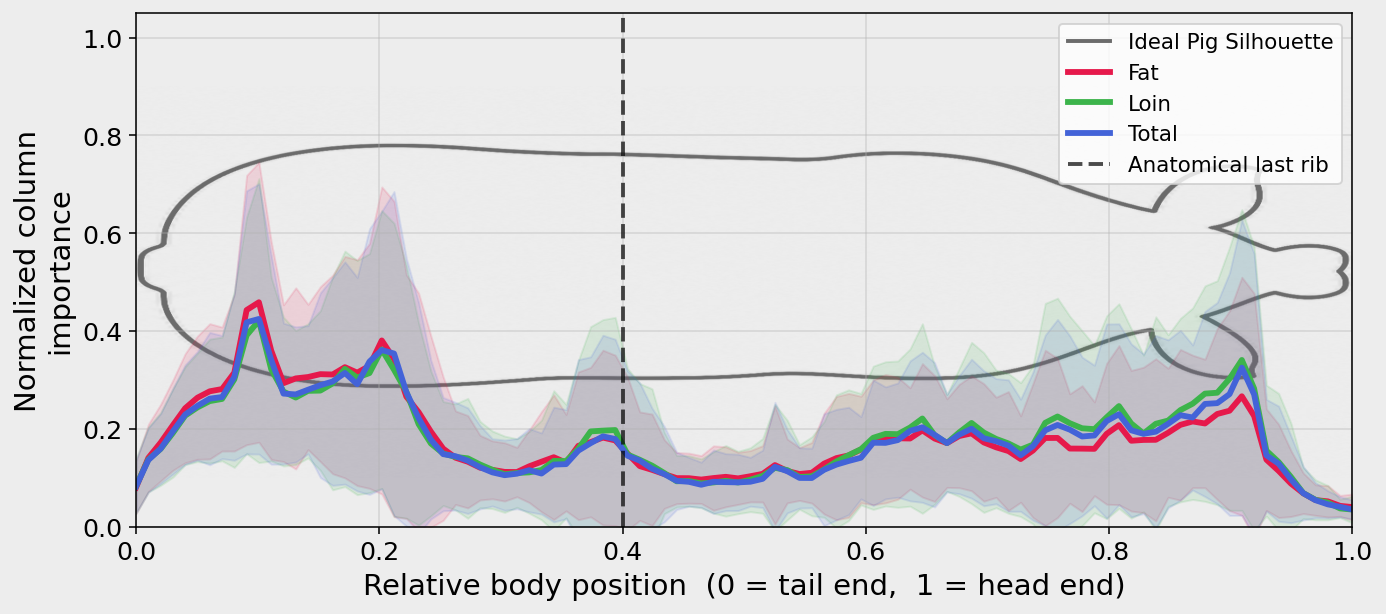
What does the model look at?
A natural worry is that PigFormer simply regresses global statistics — body volume or mean height — rather than reading local anatomy. We test this with a SmoothGrad × Input attribution summed per spine column, normalized, and averaged over all 79 test animals in shared body coordinates.
Citation
@inproceedings{bashar2026pigformer,
title = {What's Under the Skin? Estimating Swine Body Condition},
author = {Bashar, Mk and Bhatti, Kuljit and Rohrer, Gary
and Benjamin, Madonna and Brown-Brandl, Tami
and Morris, Daniel},
booktitle = {CV4Animals Workshop, IEEE/CVF Conference on Computer Vision
and Pattern Recognition (CVPR)},
year = {2026},
eprint = {2606.05611},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}